Olá pessoal, espero que estejam todos bem.
Hoje vou atender a um pedido de um colega que confessou não
ter entendido como funciona um Join.
Primeiramente devo mencionar que a teoria de banco de dados
é, em grande parte, retirada da teoria de conjuntos matemáticos. Um join
(junção) é utilizado na consulta de tabelas em conjunto, serve para que
possamos fazer consultas comparativas entre tabelas relacionadas.
Certo, então como funciona um Join?
Fazemos isso todos os dias e se tornou tão natural para nós
q não paramos mais para pensar em com é
feito.
Se tivermos três conjuntos numéricos, “Números de 1 a 10”,
“Números pares” e “Números impares” e eu quiser saber quais são os números
pares, podemos fazer um Join.
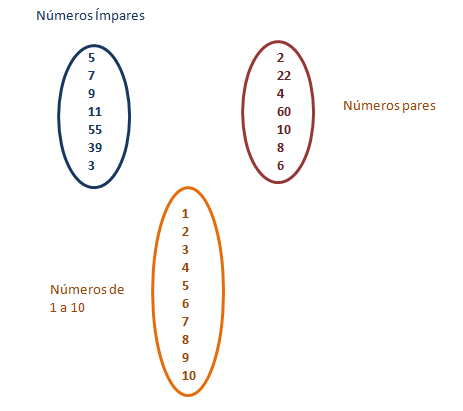
Funcionará da seguinte forma. Verificaremos quais números
estão no conjunto dos pares e em seguida compararemos esses números para ver
quais se encontram na tabela dos números de 1 a 10.

Desta forma através de comparação entre os conjuntos
chegamos a um resultado que não é nem a 1ª e nem a 2ª tabela, mas sim uma nova
tabela temporária para nossa pesquisa.
Imaginemos agora que não são conjuntos e sim tabelas e que
elas não possuem apenas um dado, mas sim PKs e Fks, digamos que é temos três
tabelas:
Funcionários {Cod_Func(PK),
Nome, Telefone}
Gerentes{Cod_Func(PK
e FK), Cod_Departamento(FK)}
Departamentos{Cod_Departamento(PK),
Nome}

Então quero saber o nome e o número de telefone dos
funcionários que são gerentes e somente destes. Na tabela funcionários não há
essa indicação e na tabela de gerentes não tenho o nome nem número de telefone.
Nesse caso devo fazer um join que me gerará uma tabela temporária com essa
informação.
Então seleciono os nomes e telefones da tabela funcionário
onde o código de funcionário da tabela funcionário seja igual ao código de
funcionário da tabela gerentes.
Em SQL:
select FUNCIONARIOS.NOME,
FUNCIONARIOS.TELEFONE
from FUNCIONARIOS, GERENTES
where FUNCIONARIOS.COD_FUNC=GERENTES.COD_FUNC;
O será gerado através da comparação entre os campos
relacionados, e serão mostrados somente os campos pedidos na seleção.

Existem três tipos de Join:
·
Inner Join: Que trará somente os resultados
que atenderem as condições nas duas
tabelas.
select FUNCIONARIOS
.NOME, FUNCIONARIOS .TELEFONE
from
FUNCIONARIOS inner join GERENTES
on
FUNCIONARIOS.COD_FUNC=GERENTES.COD_FUNC;
O resultado desta pesquisa será igual ao do
join simples.
·
Right Join: Que irá trazer como resposta todos
os resultados da tabela da direita, mesmo que não atendam a ou as condições
informadas e mais os dados que atenderem as condições e estiverem na tabela da
esquerda.
select FUNCIONARIOS.NOME, FUNCIONARIOS.TELEFONE
from FUNCIONARIOS right join GERENTES
on FUNCIONARIOS.COD_FUNC=GERENTES.COD_FUNC;

·
Left Join: Que irá trazer como resposta todos os
resultados da tabela da esquerda, mesmo que não atendam a ou as condições informadas e mais os dados que atenderem essas condições
e estiverem na tabela da direita.
select
GENRETES.COD_FUNCIONARIO, GENRETES.COD_DEPARTAMENTO
from FUNCIONARIOS left join GENRETES
on GENRETES.COD_FUNCIONARIO=FUNCIONARIOS.COD_FUNCIONARIO;

Repare que tanto em Rigth Join quanto em Left Join ocorre
repetição de elementos da tabela para evitar isso devemos usar a clausula group
by no final da sintaxe e assim agrupar os resultados.
Obrigado pela visita. Espero ter elucidado um pouco sobre o
Join!
Até o próximo post.
Bibliografia:





