Olá pessoal! Espero que estejam todos bem e evoluindo. Nesse poste vou falar sobre Modelagem Relacional
Os princípios básicos da modelagem de dados relacionais foram
referenciados a teoria de conjuntos.
“O mundo
está cheio de coisas que possuem características e se relacionam entre si”
“A lei do
mundo” de Peter P. Chen nos passa esse conceito. Tudo aquilo que pode ser
classificado ou categorizado é definido como coisa que poderá ser definido como
entidade dependendo da abordagem. Essas coisas possuem características iguais
ou semelhantes que permitem que as agrupemos. Elas irão se relacionar com
outras coisas ou outros grupos e essa será a forma de comunicação entre as
coisas.
Por que
modelar?
Modelamos
para que possamos representar o ambiente de forma que podemos prevenir futuras
correções em coisas simples que podem nos obrigar a ter trabalho em dobro na hora
de corrigirmos. Também serve com normalização e documentação do como funciona
nosso ambiente para que outras pessoas do grupo ou clientes possam entender o
que será feito e desta forma validar e aperfeiçoar os relacionamentos entre os
objetos.
Agora que já
vimos o porquê podemos passar para a parte de como e para entendermos esse tipo
de modelagem de banco de dados precisamos aprender alguns conceitos básicos à
própria modelagem.
Como
modelar?
A modelagem
de dados passa por três etapas:
Modelo
Conceitual - Representa as regras de negócio sem limitações tecnológicas ou de
implementação por isto é a etapa mais adequada para o envolvimento do usuário
que não precisa ter conhecimentos técnicos. Neste modelo temos:
·
Visão
Geral do negócio
·
Facilitação
do entendimento entre usuários e desenvolvedores
·
Possui
somente as entidades e atributos principais
·
Pode
conter relacionamentos n para m.
Modelo Lógico - Leva em conta limites impostos por algum tipo de tecnologia de banco de dados. Suas características são:
·
Deriva do modelo conceitual e via a
representação do negócio
·
Possui entidades associativas em lugar
de relacionamentos n:m
·
Define as chaves primárias das
entidades
·
Normalização até a 3a. Forma normal
·
Adequação ao padrão de nomenclatura
·
Entidades e atributos documentados
Modelo
Físico - Leva em consideração
limites imposto pelo SGBD (Sistema Gerenciador de Banco de dados) e pelos
requisitos não funcionais dos programas que acessam os dados. Características:
·
Elaborado a
partir do modelo lógico
·
Pode variar
segundo o SGBD
·
Pode ter tabelas
físicas (log , lider , etc.)
·
Pode ter colunas
físicas (replicação)
Objeto ou
Entidade:
Entidade ou
Objeto é uma representação de algo sobre o qual se deseja guardar informações.
Informações essas que devem ser compreendidas pelo sistema de informações que
será utilizado.
Podemos
identificar as entidades de três formas pelo menos:
·
Coisas
tangíveis: Tudo aquilo que é físico, que possui existência física como caderno,
mesa ou garrafa.
·
Funções:
Tudo aquilo que atua que age que pratica uma ação. Por exemplo: Professor,
Departamento, Cliente.
·
Eventos
ou Ocorrências ou Movimentação: Observado quando há algo que ocorre e continua
a ocorrer. Algo como uma ação enquanto ela está acontecendo. Exemplo:
Lançamento em conta corrente.
Atributo:
Existem três
tipos de atributos, Atributos Descritivos que são aqueles capazes de
demonstrar, representar as características do objeto, Atributos Nominativos são
aqueles que além de terem a função de descrição também identificam o objeto,
como nome ou qualquer outra informação que seja identificadora, e por último,
Atributos Referenciais que são aqueles que não necessariamente pertencem ao
objeto, mas sim fazem a relação deste com outro objeto.
Enfim, atributo
é tudo aquilo que é próprio do objeto e o diferencia perante aos demais.
Relacionamento:
Relacionamento
é uma ligação existente entre objetos. Essa relação define como é o
comportamento de um objeto, quais suas restrições, dependências e acessos a
outros objetos. A regra de negócio do banco de dados definirá se o objeto terá muitos
ou um relacionamento e qual sua cardinalidade.
Cardinalidade
é a quantidade de vezes que uma relação pode acontecer entre determinados
objetos relacionados. Seguindo a notação os relacionamentos podem ser:
·
N:
muitas vezes.
· 1:
único, somente uma vez
·
0:
não acontecer.
Então, por
exemplo: Um Professor pode ter vários Alunos, se tivéssemos dois objetos,
Professor e Aluno a o relacionamento de Professor para Aluno seria de N, pois
um professor se relaciona com vários alunos.
Opcionalidade
analise se as ocorrências de um objeto o obrigam a se relacionar com outros,
existem três:
·
Opcional:
É quando as ocorrências dos objetos que se relacionam não dependem umas das
outras.
·
Contingente:
Somente um objeto possui independência. Ou seja, um dos lados é obrigado a se
relacionar enquanto o outro não.
·
Mandatórios:
As ocorrências dos objetos existirão, somente se ambos existirem. Ou seja, os
objetos são completamente dependentes um do outro para que existam.
Os tipos
mais comuns de relacionamento são:
·
Ternário:
Quando três objetos se relacionam da mesma forma entre si.
·
Auto-Relacionamento:
É quando um objeto se relaciona consigo mesmo.
·
Agregação:
Este relacionamento possui uma condição de existência. Quando o relacionamento
é ternário e o relacionamento fundamental tem relação de N:N(muitos pra
muitos), forma-se este tipo.
·
Especialização:
É quando um grupo de objetos que possuem uma característica em comum,
geralmente deriva do desmembramento de outro objeto. Por exemplo, um objeto Pessoas,
nesse objeto pode haver vários subgrupos. Então, sendo de interesse para o
negocio, podemos separa-los.
·
Entidade
Supertipo: Possui a chave primária e os atributos comuns a todos.
·
Entidade
Subtipo: Herda a chave primária e contém os atributos específicos àquele grupo.
Restrições:
Existem
algumas restrições das quais as mais importantes, para um iniciante em
modelagem relacional, são a chave primária (primary key), unique e not
null/null.
·
Primary
Key (PK): A chave primária é um atributo que deve ser único em relação a todos
os outros da tabela, sua definição implica em assumir que este atributo também
não terá campos nulos ou repetidos e por isso não há a necessidade de defini-lo
também como unique ou not null. Essa restrição deve-se ao fato de que a PK
servirá como identificação dos dados da tabela.
A PK pode
ser simples ou composta. Ou seja, podemos definir como chave primária um
atributo ou mais desde que sejam únicos e não nulos na tabela.
Por exemplo,
o Objeto Cliente possui os seguintes atributos:
CLIENTE (cpf,
nome, sobrenome, rua, numero, cidade, nascimento).
Definimos
CPF como PK, pois não haverá registros duplicados ou nulos, sendo assim este
atributo poderá servir para identificar os demais campos da tabela.
Outro
exemplo é o Objeto Associado que possui os seguintes atributos:
ASSOCIADO (cpf_cliente, RG,
nome, sobrenome).
Neste caso a
definição de cpf_cliente e RG como chave primária se dá, pois estes atributos
não terão valores repetidos ou nulos e poderão identificar os demais campos da
tabela.
Como mencionei
existem outros conceitos de restrições como:
·
NOT
NULL: Quando um atributo não poderá receber valores nulos. Caso não seja
definido como nulo o atributo automaticamente assumirá a possibilidade de
valores nulos.
·
UNIQUE:
Quando um atributo não poderá receber valores repetidos.
Em ambos os
casos o atributo definido independerá da definição da chave.
Integridade:
Quando
fazemos o relacionamento entre objetos, normalmente desejamos que a chave
primária de um faça parte da chave do outro objeto. Isso se chama Chave
Estrangeira ou Foreign Key (FK) .
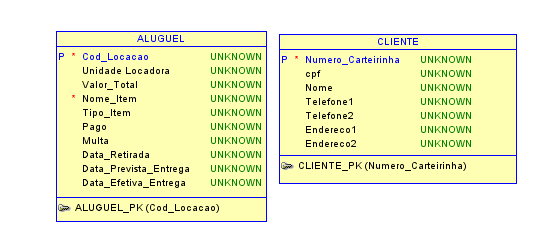
Por exemplo,
na relação entre os objetos CLIENTE e ALUGUEL de uma locadora, onde os
atributos são os seguintes:
CLIENTE(numero_carteirinha(PK),
cpf, nome)
ALUGUEL(registro_aluguel(PK),
numero_carteirinha(FK), quantidade, registro_filme, data_retirada, data_saida).
Então
sabemos que existe relação entre as tabelas e que o objeto ALUGUEL tem acesso às
informações do objeto CLIENTE através de sua chave primária.
Normalização:
Para evitar
anomalias nas inserções, exclusões e alterações de linhas e evitar redundâncias
existem as normalizações. Sendo realizadas as normalizações os dados
permanecerão confiáveis e íntegros, facilitar esse trabalho é um dos principais
objetivos da modelagem.
Existem três
formas de normalização:
·
Primeira
Forma Normal : O objetivo é retirar os
atributos ou grupos repetitivos. Temos que nos assegurar que nenhum atributo o
grupo se repete dentro do objeto de maneira a fazer com que cada linha tenha
apenas uma ocorrência de um determinado dado. Esse processo se chama
Atomicidade de Dados.
·
Segunda
Forma Normal: Estando dentro da primeira forma normal atingiremos a segunda
garantindo que todos os atributos que não forem chave sejam dependentes da
chave primária. Os atributos que não dependerem totalmente da chave primária deve
formar uma nova tabela relacionada.
·
Terceira
Forma Normal: Para termos esta normalização é necessário que a tabela já esteja
na segunda forma normal. Devemos retirar os atributos que não tiverem ligação
direta com a chave primária mesmo que este tenha ligação através de outro
atributo. Devemos verificar se haverá a necessidade de construirmos outra tabela
ou se é possível eliminar o atributo.
Certo, esse
é o conceito modelagem relacional. Importante no mundo do BI tanto para analise
de negócio quanto para a construção do modelo multidimensional.
Obrigado
pela visita e até o próximo post.
Bibliografia: