Olá, pessoal. Passei conceitos de modelagem relacional e vou
passar hoje um Passo-a-Passo baseado em um artigo que li na SQL Magazine ano 09
edição 101. Acredito que este exercício
dará uma boa base sobre modelagem e normalização. Então vamos a ele.
Utilizaremos como base de nosso modelo esta ficha de
locações da locadora. A partir dela retiraremos os objetos, relacionamentos e
normalizações.

Podemos observar que existem alguns assuntos tratados na
ficha. Nosso primeiro passo será identificar os atributos existentes e
agrupa-los em objetos.
Código Locação
Título Locado
Filme
Jogo
Data Retirada
Data Prevista Entrega
Data Efetiva Entrega
Nome
Numero Carteirinha
CPF
Telefone1
Telefone2
Endereço1
Endereço2
Multa
Pago
Valor Total
Certo, identificamos todas as informações existentes na
ficha. Passaremos ao agrupamento.
Temos dois tipos de informação básica:
·
Aluguel
Código Locação, Título Locado, Filme, Jogo, Data Retirada, Data
Prevista Entrega, Data Efetiva Entrega, Multa, Valor Total, Pago.
·
Cliente
Nome, numero da carteirinha, cpf, tel1, tel2, end1 e end2.
Teremos então a principio dois objetos:

Organizá-los e normaliza-los.
Devemos definir qual a PK de cada um dos objetos para que
possamos também depois normalizar.
Então criaremos um atributo identificador para os objetos
que não possuem ainda e, se houver, definiremos um atributo já existente como
PK.
Como temos campos de identificação nos objetos Cliente e
Aluguel, podemos defini-los. No caso do objeto Cliente podemos escolher Cpf ou
Numero da Carteirinha. Escolhi o número da carteirinha, pois poderemos assim
cadastrar os dependentes no mesmo Cpf do titular gerando novo número de
controle para o cliente na carteirinha. É claro que isso é uma escolha que deve
ser estudada com o contratante do projeto, uma vez que este pode ter outra
forma de identificar esta categoria de clientes.
Já para o objeto Aluguel defini o Código de Locação. E nosso
M.E.R ficou assim:
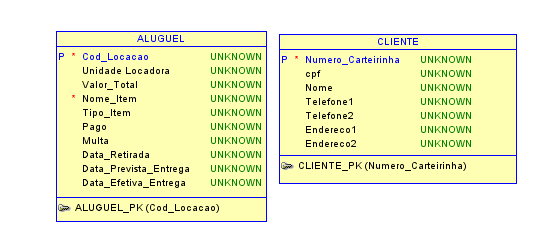
Bom, agora já temos nossas entidades como mais cara de
objeto. Vamos então normaliza-las. Você pode até pensar que a dificuldade é grande,
mas é só questão de prática. Saber as três formas normais é sempre bom para
guia-lo.
·
1FN: Não é permitida a existência de atributos
multivalorados, ou seja, um atributo não pode receber mais de um valor.
Conhecendo essa definição saberemos o que fazer, mas como
fazê-lo?
Temos que nos atentar, geralmente atributos com nomes
repetidos, diferenciado por números são multivalorados. Isso faz com que em
nosso objeto Cliente possuamos quatro atributos destes fazendo referência a
telefone: telefono1, telefone2 e a endereço: endereço1 e endereço2. Devemos
então criar novos objetos para esses atributos e relacioná-los com o objeto
Cliente por suas PKs como FK, pois estes atributos podem conter mais de um
valor sabendo que o cliente pode ter mais de um tel e mais de um endereço para
cadastro. Sendo assim criarei os objetos Telefone e Endereço com os atributos
correspondentes e uma PK que será criada para cada.

O objeto Aluguel possui três atributos como data, podemos
separa-los também criando um novo objeto Datas. Temos também dados relacionados
ao item que foi alugado e se é jogo ou filme. Também podemos observar que
existem dois atributos que podem ter valor sim ou não, são eles Multa e Pago.
Devemos criar entidades para ambos e criar PKs também.

·
2FN: Deve estar na primeira forma normal. Todas
as colunas devem ser totalmente dependentes da PK.
Os objetos relacionados ao
Cliente não necessitam de mais normalizações.
O objeto aluguel em si já está na
segunda forma normal também.
Já com relação ao objeto Item podemos
então separa-lo em dois objetos. O Tipo_Item que nos dirá se é filme e o próprio
Item.

·
3FN: Deve estar na segunda forma normal. Não
pode haver atributos que tenham origem de cálculo derivados de outros
atributos.
Esses atributos geralmente são os relacionados a algum
cálculo que seja feito para fim de relatório ou conhecimento de valores. Nesse
momento temos que verificar que, para que o atributo Valor_Total do objeto
Aluguel possa ter alguma informação, precisamos saber quais os valores dos
filmes, jogos e multas.
Podemos criar um novo objeto que conterá esses valores. Chamarei
de Financeiro e conterá os atributos:
·
Financeiro:
Cod_Financeiro, Valor_Jogo, Valor_Filme, Valor_Multa.

Tendo normalizado nossos objetos podemos começar a verificar
seus relacionamentos e duplicidades.
Sabemos que em nossa ficha de aluguel temos atributos
referentes aos clientes, então é lógica uma relação entre esses objetos. O
objeto Aluguel também deve receber a chave estrangeira dos objetos Data e Item
já que precisará das informações referentes a estes. O objeto Item precisa das informações
sobre Tipo dele (se é filme ou jogo) então relacionaremos Item e Tipo_Item. O
objeto Tipo_Item poderá relacionar-se aos objetos Financeiro, assim saberemos
os valores unitários de cada tipo de item (filme, jogo e consideraremos multa
como item, para efeito de cálculos). Em um M.E.R. coloca-se também o tipo de
relacionamento que um objeto tem com o outro, geralmente informado por um verbo
(“tem”, “possui”, “recebe”, “faz”, etc...).
Com os relacionamentos nosso M.E.R. ficará desta forma:

Lembre-se que não existe um modelo certo ou errado e sim um
modelo mais ou menos eficaz o que vai depender das exigências de negócio do
cliente.
Após isso se inicia a faze do modelo físico que levará em
conta tipo e capacidades da plataforma de banco de dados que será utilizado.
Podendo então definir tipo dos dados que os atributos receberão.
Mas pararemos por aqui, por enquanto espero que ajude a
entender um pouco mais o passo a passo e assim fixar melhor as informações
sobre modelagem.
Obrigado pela visita e até o próximo post.
Bibliografia:
Revista SQL Magazine - Ano 9 :: Edição101. Artigo: Normalização de dados na prática; por Roberto de Angelo Jr.






